This blog has been migrated to a serverless architecture.
Posted by Sébastien Stormacq in Migration on 15/10/2018
Visit Seb in the Cloud
Today, I migrated this blog from Wordpress to a serverless infrastructure. I also switched to Jekyll blog engine and adopted a more modern look & feel.
Read more about the details of the migration.
Java EE Containers and Docker
Posted by Sébastien Stormacq in IBM, Java, Oracle on 04/08/2014
Docker is an open platform for developers and sysadmins to build, ship, and run distributed applications. Given my long history with Java EE, it was natural for me to experiment the installation and deployment of popular Java EE containers using Docker.
Communities and Software vendors did not wait for me, and I discovered many prebuilt containers, ready to use.
The list below references official builds, i.e. the ones created and maintained by the software vendor. (by alphabetical list)
- Oracle – GlassFish 4.0.1 (thanks Alexis)
- IBM – WebSphere Liberty Profile
- JBoss – Wildfly
- Oracle – WebLogic 12c
I also built my own Dockerfile for Glassfish.
Feel free to comment this post, I will update the list. (Official builds only)
Enjoy !
Using AWS T2 Instance Type on AWS Elastic Beanstalk
Posted by Sébastien Stormacq in Amazon on 28/07/2014
 |
Should you want to migrate existing AWS Elastic Beanstalk applications to T2 instance type, you can follow this 8 steps tutorial on AWS official’s blog.
Enjoy ! |
Build and Deploy a Federated Web Identity application
Posted by Sébastien Stormacq in Amazon on 22/06/2014
| My second blog post has been published last week on aws.amazon.com/blogs. It details how to build and deploy a web application that uses Web Identity Federation on AWS Elastic Beanstalk. This application uses Login with Amazon as an example. As usual, do not hesitate to send your comments and feedback. Enjoy ! |  |
Mac OS X makes handling SSH keys easier
Posted by Sébastien Stormacq in Apple, General, Mac OS X on 06/05/2014
I discovered something this Sunday morning that will make my day, week and month 🙂
If you don’t know much about ssh-agent or if you’re looking for a tutorial about using ssh public key authentication or ssh-agent, read one of the excellent articles linked from here before to continue here.
On OSX, Apple made it much easier to manage your SSH keys and to work with SSH, by adding two welcome improvements
- They added
ssh-agentto launchd(8) - They added
ssh-agentsupport for KeyChain
The first improvement alleviate user’s need to manually start ssh-agent for every session. launchd(8) will also makes sure ssh-agent is automatically restarted in case of crash.
Launchd configuration file is here:
hostname:~ user$ cat /System//Library/LaunchAgents/org.openbsd.ssh-agent.plist <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version="1.0"> <dict> <key>Label</key> <string>org.openbsd.ssh-agent</string> <key>ProgramArguments</key> <array> <string>/usr/bin/ssh-agent</string> <string>-l</string> </array> <key>ServiceIPC</key> <true/> <key>Sockets</key> <dict> <key>Listeners</key> <dict> <key>SecureSocketWithKey</key> <string>SSH_AUTH_SOCK</string> </dict> </dict> <key>EnableTransactions</key> <true/> </dict> </plist> |
But the best part is the second improvement : instead of storing your keys in .pem files in your ~/.ssh directory, you can tell ssh-agent to store your keys in the more secured KeyChain trusted store, as show on the picture below.
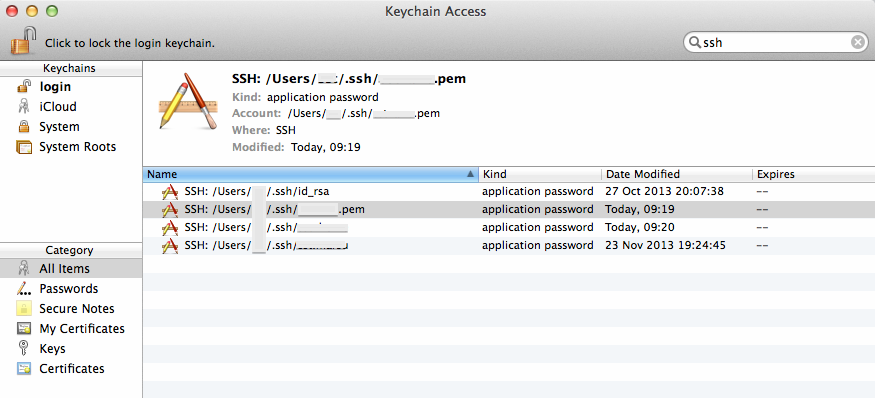
Apple silently added a -K option to ssh-add command to instruct ssh-add to store your SSH key in KeyChain in addition to loading the key in memory. ssh-agent will search for keys in their usual location on disk but also in Keychain.
What are the benefits of this?
There is no more need to explicitly call ssh-add when your session start, like you used to do in your .profile or .bashrc file. LaunchD will load ssh-agent and will instruct it to load keys referenced in your KeyChain. Note that the .pem file is not stored into KeyChain, you can not delete these from your file system.
Finally, because Keychain might synchronise across your machines through iCloud, your keys’ password are now available automatically on all your machines (provided you’re willing to keep a copy of your keys in iCloud – but that’s a different story)
Enjoy!
Six steps to deploy Ghost to AWS Elastic Beanstalk
Posted by Sébastien Stormacq in Amazon on 05/05/2014
A month ago, my first blog post was published to Amazon’s official Application Deployment Blog : “Six steps to deploy Ghost to AWS Elastic Beasntalk“.
Update : since this article was published, Amazon released Amazon Linux version 2014.03. Steps 3-6 are not required anymore 🙂 Deploying Ghost to AWS Elastic Beanstalk is even easier today.
Enjoy !
Storing Apache Access and Error Logs to Amazon S3 with Fluentd
Posted by Sébastien Stormacq in Amazon on 01/05/2014
It’s been a while I did not write a new blog post. I joined Amazon Web Services a year ago and our company policy is to not blog about our products and services, but rather refer to our official blogs.
However we can talk about other products and services and today I would like to share some experiments I made while preparing a training class, using Fluentd. Fluentd is an open-source data collector designed for processing data streams. Many use Fluentd to collect and aggregate log files.
Fluentd is able to parse many different input files. It produces aggregated JSON files and stream them to your destination of choice : a central Fluentd aggregation server, a database, a file storage on prem or in the cloud.
Fluentd’s documentation is very complete and clear and the community extremely reactive and willing to help. For basic instructions to collect and aggregate Apache’s HTTP Server log files and to push them to Amazon S3, please read this excellent article. I will not repeat the basic configuration instructions here.
However I had to struggle with two configuration problems and I thought it was worth to share these and their solutions to benefit the wider Fluentd community.
Problem #1 : Fluentd has no standard parser for Apache’s HTTP Server error_log file
The in_tail plugin is able to parse a couple of file formats by default, including Apache’s HTTP Server access_log file, using a configuration like this :
<source> type tail format apache2 path /var/log/httpd/access_log pos_file /var/log/td-agent/httpd.access_log.pos tag s3.apache.access </source>
However, when it comes to error_log file, Apache’s HTTP Server uses a slightly different format and in_tail plugin will fail to parse it. Fortunately, in_tail allows to define your own regular expression for parsing message. After a bit of experiment, I managed to craft a regular expression to parse the error_log file :
^\[[^ ]* (?<time>[^\]]*)\] \[(?<level>[^\]]*)\] \[pid (?<pid>[^\]]*)\] \[client (?<client>[^\]]*)\] (?<message>.*)$
My configuration for the error_log parser is as this :
<source> type tail format /^\[[^ ]* (?<time>[^\]]*)\] \[(?<level>[^\]]*)\] \[pid (?<pid>[^\]]*)\] \[client (?<client>[^\]]*)\] (?<message>.*)$/ path /var/log/httpd/error_log pos_file /var/log/td-agent/httpd.error_log.pos tag s3.apache.error </source>
Problem #2 : Fluentd’s Amazon S3 output plugin does not generate true JSON by default
I want to push all my aggregated log to Amazon S3 for storage and further analysis with Amazon Elastic Map Reduce. Fluentd has an output plugin to push the stream to Amazon S3. Unfortunately, by default, this plugin uses the following data format :
date\ttag\t{... JSON ...}
This is not true JSON and makes it difficult to analyse the JSON stream with standard parsers (or Serde if you plan to use Apache’s Hive) . To configure the plugin to use pure JSON as output, you just need to add the following lines (in bold below) :
<match s3.*.*> type s3 s3_bucket bucket_name path logs/ buffer_path /var/log/td-agent/s3 time_slice_format %Y%m%d%H time_slice_wait 10m utc format_json true include_time_key true include_tag_key true buffer_chunk_limit 256m </match>
The first line will tell the plugin to use pure JSON, the two other lines ensure you don’t loose the date and tag information by pushing them back to the JSON structure.
This configuration produce entries like this one, easy to parse and to analyse
{"host":"62.999.999.999","user":null,"method":"GET","path":"/dreambox-second-stage-bootloader-update/","code":200,"size":28377,"referer":null,"agent":"Mozilla/5.0 (X11; Linux x86_64; rv:15.0) Gecko/20100101 Firefox/15.0.1","tag":"s3.apache.access","time":"2014-05-01T09:27:23Z"}
In addition to this Fluentd configuration, you want to be sure only Fluentd is able to write to your Amazon S3 log storage bucket. When using Fluentd on an Amazon EC2 instance, you can use the following permissions attached to an IAM Role :
{
"Effect": "Allow",
"Action": [
"s3:Get*", "s3:List*","s3:Put*", "s3:Post*"
],
"Resource": [
"arn:aws:s3:::bucket_name/logs/*", "arn:aws:s3:::bucket_name"
]
}
A big kudo and thanks to @tagomoris and @repeatedly for your help to configure this.
Enjoy !
Python Script for AWS’ Route 53 API Authentication
Posted by Sébastien Stormacq in Amazon on 12/04/2013
[UPDATE – March 2014]
This blog post was about discovering the low level details about AWS API signature. Additional signature methods are available today.
I would not recommend anyone to actually use the type of scripts explained below or to manually compute signatures. You can rely on AWS SDK s to do that automatically for you (see an example here).
Nevertheless, enjoy the reading 🙂 !
[/UPDATE]
In my last post entry – Setting Up a Private VPN Server on Amazon EC2 – I end up by providing tips to rely on a fixed DNS name every time you start your server.
For the impatient : the full script is available on GitHub. For all the others, let’s understand the problem and the proposed solution.
Why automating DNS configuration ?
This is a common problem with public cloud machines : at every start, the machine receives a different public IP address and public DNS name. There are two methods to keep a consistent name to access your machine :
- bundle a Dynamic DNS client (such as inadyn) and access your machine through its DynDNS domain name.
- create a DNS A (address) or CNAME record (an alias) to point to the public IP address of your machine
The latter solution is only valid if you have your own domain name. It offers the maximum flexibility as you can configure the DNS as you need.
To automatize the task, your DNS provider must provide you with a programmatic way to change its configuration : an API. This is exactly what Amazon’s Route 53 DNS Service offers you.
To complete my previous article, I choose to add at the end of my script a command to dynamically associate the instance public IP name to my own domain name, such as myservice.aws.stormacq.com. I choose to define an alias to the public DNS name setup by AWS, using a CNAME record.
How to programmatically configure your Route 53 DNS ?
AWS’ Route 53 API is RESTful, making it easy to manipulate it with command line, using “curl” command for example. curl can be used to issue GET requests to read configuration data and POST requests to change DNS configuration.
Requests payload is defined in XML. An example GET query would be
<?xml version="1.0"?> <ListHostedZonesResponse xmlns="https://route53.amazonaws.com/doc/2012-12-12/"> <HostedZones> <HostedZone> <Id>/hostedzone/MY_ZONE_ID</Id> <Name>aws.mydomain.com.</Name> <CallerReference>22F684C6-3886-3FFF-8437-E22C5DCB56E7</CallerReference> <Config> <Comment>AWS Route53 Hosted subdomain</Comment> </Config> <ResourceRecordSetCount>4</ResourceRecordSetCount> </HostedZone> </HostedZones> <IsTruncated>false</IsTruncated> <MaxItems>100</MaxItems> </ListHostedZonesResponse> |
To restrict access to your DNS configuration, the API requires authentication. Route 53 mandate the use of a proprietary HTTP header to authenticate requests.
Full details about Route 53 API is available on Amazon’s documentation.
The problem when using authentication and curl
AWS’ Route 53 authentication is described with great details and examples in the official documentation. Basically, it is based on a HMAC signature computed from the current date/time and your AWS Secret Key.
The HTTP header to be added to the request is as following
AWS3-HTTPS AWSAccessKeyId=MyAccessKey,Algorithm=ALGORITHM,Signature=Base64( Algorithm((ValueOfDateHeader), SigningKey) ) |
The Algorithm can be HMacSHA1 or HMacSHA256. The date is the current system time. You can use your system time or you can ask AWS what is their system time. The latter needs an additional HTTP call but this method will avoid time synchronisation issues between your machine and AWS. While curl is very versatile and can accommodate to many different situations, it can not compute an HMac signature to send as authentication header, a short python script is my solution.
The Python Solution
I choose to wrap the curl call into Python, let Python compute the signature, generate the appropriate HTTP header and then call curl, passing all remaining command line arguments to curl itself. The general idea is as following :
- collect AWS_ACCESS_KEY and AWS_SECRET_KEY
- Compute the Signature
- Call curl with correct parameters to inject the authentication HTTP header and all command line parameters we have received
Signature
The signature is generated with this code. It receives two String as input (the text to sign and the key). I hard-coded the algorithm. The function returns the base64 encoded signature.
def getSignatureAsBase64(text, key): import hmac, hashlib, base64 hm = hmac.new(bytes(key, "ascii"), bytes(text, "utf-8"), hashlib.sha256) return base64.b64encode(hm.digest()).decode('utf-8') |
AWS’s date
Retrieving AWS’s date is similarly easy
def getAmazonDateTime(): import urllib.request httpResponse=urllib.request.urlopen("https://route53.amazonaws.com/date") httpHeaders=httpResponse.info() return httpHeaders['Date'] |
Formatting the header
And the header is formatted with
def getAmazonV3AuthHeader(accessKey, signature): # AWS3-HTTPS AWSAccessKeyId=MyAccessKey,Algorithm=ALGORITHM,Signature=Base64( Algorithm((ValueOfDateHeader), SigningKey) ) return "AWS3-HTTPS AWSAccessKeyId=%s,Algorithm=HmacSHA256,Signature=%s" % (accessKey,signature) |
Calling curl
Finally, we just have to call the curl command :
import subprocess curlCmd = ["/usr/bin/curl", "-v" if DEBUG else "", "-s", "-S", "--header", "X-Amzn-Authorization: %s" % AWS_AUTH, "--header", "x-amz-date: %s" % AWS_DATE] curlCmd += args.curl_parameters curlCmd += [args.curl_url] logging.debug(" ".join(curlCmd)) return subprocess.call(curlCmd) |
The full script is available under a BSD license on GitHub. There is some additional plumbery to handle command line arguments, to load the AWS credentials etc … which is out of the scope of this article.
Conclusion
Using this script, you can easy use curl command to GET or POST REST requests to Route 53’s API.
I am using this script to create custom CNAME records whenever an EC2 instance is started, allowing me to reuse a well known, stable DNS public name to access my instance. A sample XML to define a CNAME is posted on GitHub together with the source code.
Enjoy !
Build a private VPN Server on Amazon’s EC2
Posted by Sébastien Stormacq in Amazon on 26/03/2013
[UPDATE March 2014]
Do not copy paste the code from the core text of this post. These are one year old scripts. An updated version is available in my GitHub Repository.
[/UPDATE]
This article describes how to run your private VPN gateway in Amazon’s cloud. Although this article describes a 100% automatic (scripted) method to start and configure your VPN server, it assumes some basic knowledge of Amazon’s EC2 platform and – obviously – requires you to have an account on EC2.
If you are totally new to EC2, I strongly advise you to follow a Getting Started guide before going through this article.
The VPN server I am using for the purpose of this article is based on IPSec / L2TP security protocols implemented by open source projects OpenSWAN and XL2LTP.
For the impatient, the scripts are available on github, along with basic configuration and setup information. Should you need more details, I encourage you to read the following.
Why a private VPN server ?
Sometime, it is legitimate to create an encrypted tunnel of data to another machine on the internet. Think about situations like
- Being connected on a public network in an hotel, a conference, a restaurant or coffee shop
- Willing to escape your ISP or Service Provider limitations (Belgium DNS Blocking, French Hadopi, …)
- Accessing services not being distributed in your country (Deezer, Spotify etc ..)
- or simply to ensure no one can snoop your network traffic
How to start a customised machine on EC2 ? Some Background.
AWS provides several ways to start customised machines. Either you can create your own virtual machine image (AMI) based on one of the many images available. Either you can start a standard image and run a script at startup time to customise it. Either you can boot from an EBS backed machine image (AMI) and create a snapshot of your root volume.
The first method is more labor intensive (install the software, maintain the image, …) and more expensive (you have to pay for the storage of your customised image) but has the advantage of faster startup times as the image does not need to install and to configure required softwares at boot time.
Running a script at boot time is easier as you do not need to enter into the details of creating and maintaining custom images. It is cheaper as you do no need to store that custom image. But the machine is slower to boot as it requires to download, install and configure required softwares at every boot. This is the method I choose to setup the VPN server.
The latter method (EBS Snapshot of root volume) is described in extenso in the documentation and – based on my own experience – provides the best ratio between labour, price and effectiveness. This is probably the method I would recommend for production workloads.
But … How to start a customisation / installation script just after booting a standard linux distribution or one of the prepared Amazon Machine Image ? This is where cloud-init kicks in.
Cloud-Init is an open source library initiated by Canonical (the maker Ubuntu) to initialise Virtual Machines running in the cloud. It allows, amongst others, to do post-boot configuration like
- setting the correct locale
- setting the hostname
- initialising (or installing) ssh keys
- setup mount points
- etc …
It also allows to pass a user defined script to the instance to perform any additional setup and configuration tasks. This is the technique I am using to download, install, configure and start IPSec and L2TP daemons on the server.
Cloud-Init is included by default in Ubuntu machine images and in Amazon Linux machine images on EC2.
For the purpose of this article, I choose to use the Amazon Linux machine image because it is lightweight and specifically designed to run on EC2.
This is enough background information, let’s start to do real stuffs.
How to start a machine from your command line ?
To start an EC2 instance form your machine command line, you will need the following :
- an Amazon Web Service account and a credit card 🙂
- to create a SSH key pair
- to create a VPN security group
The VPN Security Group must allow TCP and UPD port 500 and UPD port 4500 as shown on the screenshot below.
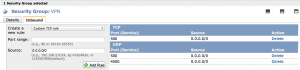
VPN Security Group
Please refer to the getting started guide to learn how to perform these. Be sure to write down the name of your key pair and the name of your security group as we will need these later.
Once your basic setup of EC2 is done, you will need to install and configure EC2 Command line tools on your machine.
- Download and Install EC2 Command Line Tools
- Configure your environment
To configure your environment, you will need to setup a couple of environment variables, typically in $HOME/.profile
- EC2_HOME environment variable points to command line tools
- EC2_URL environment variables contains AWS endpoint (http://docs.aws.amazon.com/general/latest/gr/rande.html#ec2_region)
- AWS_ACCESS_KEY environment variable contains your AWS access key
- AWS_SECRET_KEY environment variable contains your AWS secret key
Do not change the name of these environment variables as these are used in the script.
For example, here is my own .profile file (on Mac OS X) :
export JAVA_HOME=`/usr/libexec/java_home` export EC2_HOME=/Users/sst/Projects/aws/ec2-api-tools-latest export AWS_ACCESS_KEY=<access key> export AWS_SECRET_KEY=<secret key> export EC2_URL=http://ec2.eu-west-1.amazonaws.com |
Once this setup is done, you can start to use the EC2 command line tools as demonstrated in the script below :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #to be run on my laptop # create and start an instance #AMI = AMZN Linux 64 Bits #AMI_DESCRIPTION="amazon/amzn-ami-pv-2012.09.0.x86_64-ebs" AMI_ID=ami-c37474b7 KEY_ID=sst-ec2 SEC_ID=VPN BOOTSTRAP_SCRIPT=vpn-ec2-install.sh echo "Starting Instance..." INSTANCE_DETAILS=`$EC2_HOME/bin/ec2-run-instances $AMI_ID -k $KEY_ID -t t1.micro -g $SEC_ID -f $BOOTSTRAP_SCRIPT | grep INSTANCE` echo $INSTANCE_DETAILS AVAILABILITY_ZONE=`echo $INSTANCE_DETAILS | awk '{print $9}'` INSTANCE_ID=`echo $INSTANCE_DETAILS | awk '{print $2}'` echo $INSTANCE_ID > $HOME/vpn-ec2.id # wait for instance to be started DNS_NAME=`$EC2_HOME/bin/ec2-describe-instances --filter "image-id=$AMI_ID" --filter "instance-state-name=running" | grep INSTANCE | awk '{print $4}'` while [ -z "$DNS_NAME" ] do echo "Waiting for instance to start...." sleep 5 DNS_NAME=`$EC2_HOME/bin/ec2-describe-instances --filter "image-id=$AMI_ID" --filter "instance-state-name=running" | grep INSTANCE | awk '{print $4}'` done echo "Instance started" echo "Instance ID = " $INSTANCE_ID echo "DNS = " $DNS_NAME " in availability zone " $AVAILABILITY_ZONE |
You will need to slightly customise this script to make it run :
- Line 5 : check what is the AMI ID in your geography
- Line 6 : replace “sst-ec2” with the name of your ssh key pair
- Line 7 : replace “VPN” with the name you choose for your Security Group
How is it working ?
10 11 12 | echo "Starting Instance..." INSTANCE_DETAILS=`$EC2_HOME/bin/ec2-run-instances $AMI_ID -k $KEY_ID -t t1.micro -g $SEC_ID -f $BOOTSTRAP_SCRIPT | grep INSTANCE` echo $INSTANCE_DETAILS |
This script starts an EC2 instance (line 11) of the given type with the specified SSH key pair and Security Group. It uses the “-f” option to pass a cloud-init user data script that will download install and configure IPSec and L2TP once the machine is booted.
18 19 20 21 22 23 24 25 26 | # wait for instance to be started DNS_NAME=`$EC2_HOME/bin/ec2-describe-instances --filter "image-id=$AMI_ID" --filter "instance-state-name=running" | grep INSTANCE | awk '{print $4}'` while [ -z "$DNS_NAME" ] do echo "Waiting for instance to start...." sleep 5 DNS_NAME=`$EC2_HOME/bin/ec2-describe-instances --filter "image-id=$AMI_ID" --filter "instance-state-name=running" | grep INSTANCE | awk '{print $4}'` done |
The script then waits for the machine to be ready (lines 19-26) and, once available, the script reports the machine public DNS name (to be used to configure your VPN client software) (line 30 – 31)
How to Install and to Configure VPN into your new machine ?
Now that the machine is started, it receives the customisation script through the -f option. Cloud-Init will execute this script to finalise the setup of the machine.
Here is the script allowing to install and configure IPSec and L2TP automatically. Some details are given after the code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | #!/bin/sh # Please define your own values for those variables IPSEC_PSK=SharedSecret VPN_USER=username VPN_PASSWORD=password # Those two variables will be found automatically PRIVATE_IP=`wget -q -O - 'http://instance-data/latest/meta-data/local-ipv4'` PUBLIC_IP=`wget -q -O - 'http://instance-data/latest/meta-data/public-ipv4'` yum install -y --enablerepo=epel openswan xl2tpd cat > /etc/ipsec.conf <<EOF version 2.0 config setup dumpdir=/var/run/pluto/ nat_traversal=yes virtual_private=%v4:10.0.0.0/8,%v4:192.168.0.0/16,%v4:172.16.0.0/12,%v4:25.0.0.0/8,%v6:fd00::/8,%v6:fe80::/10 oe=off protostack=netkey nhelpers=0 interfaces=%defaultroute conn vpnpsk auto=add left=$PRIVATE_IP leftid=$PUBLIC_IP leftsubnet=$PRIVATE_IP/32 leftnexthop=%defaultroute leftprotoport=17/1701 rightprotoport=17/%any right=%any rightsubnetwithin=0.0.0.0/0 forceencaps=yes authby=secret pfs=no type=transport auth=esp ike=3des-sha1 phase2alg=3des-sha1 dpddelay=30 dpdtimeout=120 dpdaction=clear EOF cat > /etc/ipsec.secrets <<EOF $PUBLIC_IP %any : PSK "$IPSEC_PSK" EOF cat > /etc/xl2tpd/xl2tpd.conf <<EOF [global] port = 1701 ;debug avp = yes ;debug network = yes ;debug state = yes ;debug tunnel = yes [lns default] ip range = 192.168.42.10-192.168.42.250 local ip = 192.168.42.1 require chap = yes refuse pap = yes require authentication = yes name = l2tpd ;ppp debug = yes pppoptfile = /etc/ppp/options.xl2tpd length bit = yes EOF cat > /etc/ppp/options.xl2tpd <<EOF ipcp-accept-local ipcp-accept-remote ms-dns 8.8.8.8 ms-dns 8.8.4.4 noccp auth crtscts idle 1800 mtu 1280 mru 1280 lock connect-delay 5000 EOF cat > /etc/ppp/chap-secrets <<EOF # Secrets for authentication using CHAP # client server secret IP addresses $VPN_USER l2tpd $VPN_PASSWORD * EOF iptables -t nat -A POSTROUTING -s 192.168.42.0/24 -o eth0 -j MASQUERADE echo 1 > /proc/sys/net/ipv4/ip_forward iptables-save > /etc/iptables.rules cat > /etc/network/if-pre-up.d/iptablesload <<EOF #!/bin/sh iptables-restore < /etc/iptables.rules echo 1 > /proc/sys/net/ipv4/ip_forward exit 0 EOF service ipsec start service xl2tpd start chkconfig ipsec on chkconfig xl2tpd on |
As promised, here are some details
- Lines 4-6 defines your security credentials for the VPN. They must be changed before executing this script.
- Line 12 uses yum to install IPSec & L2TP implementation (OpenSWAN and xl2tpd) from the Amazon’s provided EPEL repository
- Lines 14-93 creates IPSec and L2TP configuration files, reusing the credentials you provided at the head of the script.
- Lines 95-96 setup proper network NATing
- Lines 98-105 ensure the network NATing settings will be restored in case the network interface is shutdown and up again.
- Finally, lines 107-110 start required services and ensure they will be restarted in case of reboot.
Congrats for those of you still reading. You now should have a valid VPN server running in the cloud. If everything went well, you should now be able to configure your VPN client.
How to connect from Mac OS X ?
Once the server is up and running, you simply add a VPN interface in your Network Preferences
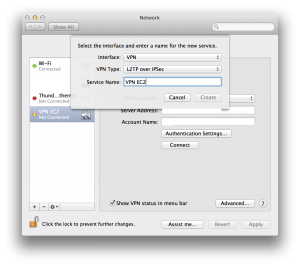
Then, use the public DNS hostname as server address and your username, as shown below
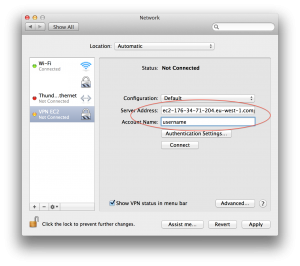
Finally, click on “Authentication Settings” to enter the shared secret and your password.
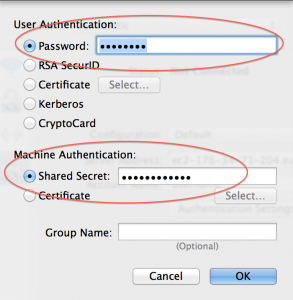
Then click on Apply, then Connect
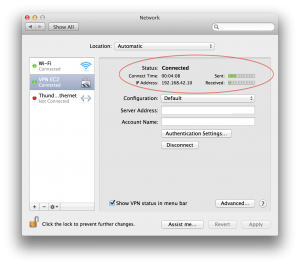
If everything is OK, you should connect to your new VPN Server.
How to be sure you’re connecting through the VPN ?
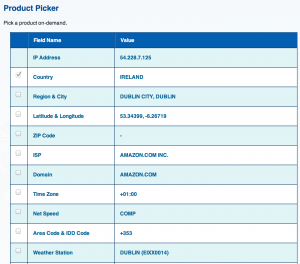
The easiest way to check that indeed all your network traffic is routed through the VPN tunnel is to connect to one of the many IP Address Geolocalisation web sites.
The web site I found on Google reported an Amazon IP address from Ireland, which is the geographical region I choose to deploy my VPN server.
A note for Windows users
Microsoft published an extensive technical note describing the details of setting up a IPSec client on Windows.
Also, Windows does not support IPsec NAT-T by default, which is used whenever the server is behind a NAT (as in this case). You have to add a registry key to enable this – see http://support.microsoft.com/kb/926179/en-us (still applies to Windows 8)
How to hook up a DNS alias to avoid to change client configuration ?
Every time you will startup a new VPN server, you will need to enter its public DNS name to your VPN client configuration. It is possible to avoid this if you have a domain name of your own, just by creating a DNS CNAME record pointing to the public DNS address of your server, such as
vpn.mydomain.com CNAME ec2-176-34-71-204.eu-west-1.compute.amazonaws.com.
If you are using Amazon’s Route 53 DNS service, this step can be entirely automated using scripts. More about this in another article.
Congrats if you manage to read this article to the end. Once again, the script source code is available on GitHub.
Enjoy !
Devoxx 2012
Posted by Sébastien Stormacq in IBM, iPhone, Java, Personal on 11/11/2012
Tomorrow, Antwerp will host – for the 11th year in a row – the biggest European Java Developers conference : Devoxx.
This year I will celebrate my 10th Devoxx attendance ! And for the first time I will have the pleasure to host two talks.
On Monday at 18:05 (Room #9), during a “Tools in Action” session, my colleague Abdoul and myself will build, live in front of the audience, a mobile application allowing to take pictures and capture geo localisation information and to send these for publishing on a web site. This demo will be built with open-source frameworks like DoJo and Apache’s Cordova, using IBM’s Worklight development IDE. The architecture for this demo is depicted here under.

On Wednesday at 16:40 (Room #6), during the Conference, my colleague Eric and myself will demonstrate how IBM Rational Team Concert can be used to manage the lifecycle of a mobile application development, from capturing requirements to tests execution, changes and bugs management etc …
The rest of the time, you will find me on IBM’s booth in the exposition ground floor.
For those not knowing what Devoxx ambiance is, check out this nice video. Devoxx is sold out (again) this year : 3400 attendees from 40 different countries.